Dear Customers,
SENSE mRNA-Seq Library Prep Kits (Cat. No. 001.24 and 001.96) are being discontinued. We recommend instead to use our CORALL mRNA-Seq Library Prep Kit.
Description
SENSE mRNA-Seq Library Prep Kit
SENSE is a complete strand-specific mRNA-Seq library prep kit for accurate gene expression profiling, transcriptome sequencing, discovery and quantification of antisense transcripts and overlapping genes.
Superior Strand-Specificity
The strand-displacement stop/ligation technology used in SENSE generates fewer antisense artifacts which can be produced by template-switching in protocols which utilize RNA or cDNA fragmentation. This results in exceptional (>99.9 %) strand-specificity and reduced experimental noise, enabling the detection and quantification of antisense transcripts with high confidence.
Rapid Turnaround
NGS-ready libraries can be produced from total RNA samples in under 5 hours with less than 50 % hands-on time, allowing RNA extraction, library preparation and quality control to be performed in one day.
All-in-One Solution
No additional kits or reagents for poly(A) RNA selection, library amplification, size selection or purification, or barcodes are required.
Low Amount of Input Total RNA
The typical amount of input total RNA is 1 ng – 2 µg.
Efficient rRNA Elimination
Different Sequencing Read Length
For good representation and even coverage of all transcripts in your experiment the library should have a size suitable for the chosen sequencing read length. The size of SENSE libraries for Illumina can be adjusted by simply modulating appropriate buffers during reverse transcription/ligation and purification steps.
Compatibility
Simple Multiplexing
Workflow
The SENSE kit features an all-in-one mRNA-Seq library preparation protocol. Most of the procedure is performed on magnetic beads, making it amenable to automation and decreasing purification time. The SENSE protocol has a simple workflow consisting of just 3 major steps.
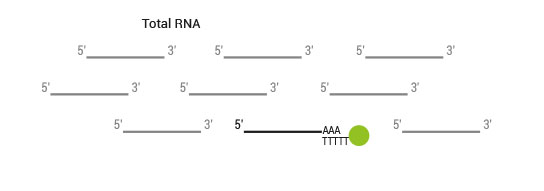
Please find a schematic overview of the workflow for SENSE mRNA-Seq for Illumina below:
to resolve secondary structures and promote efficient hybridization.

![]()
specifically bind polyadenylated RNAs. RNAs lacking a poly(A) tail are
then washed away, leaving only purified poly(A) RNA hybridized to the
beads.
![]()
all traces of cytoplasmic rRNA, tRNA, and other non-polyadenylated RNAs
are removed.

![]()
stop/ligation technology. The starter/stopper heterodimer mix is randomly
hybridized to the poly(A) RNA still bound to the magnetic beads.
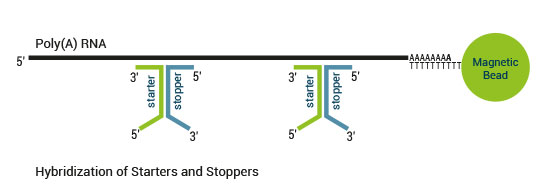
![]()
to the next
hybridized heterodimer, where the newly synthesized cDNA insert
is ligated
to the stopper.
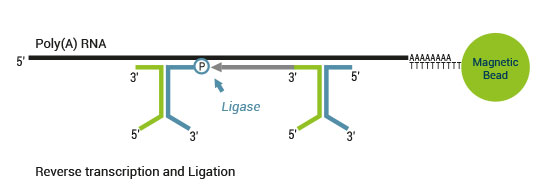
![]()
conditions for the RT/ligation reaction
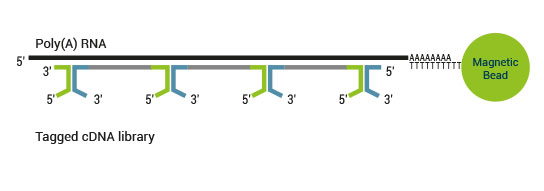
![]()
converted to double-stranded DNA. The double-stranded library is purified
to remove magnetic beads and second strand synthesis reaction components.
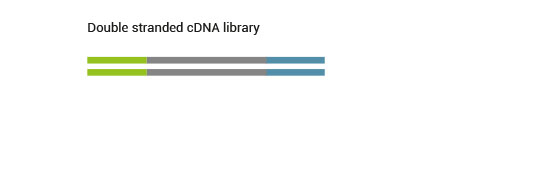
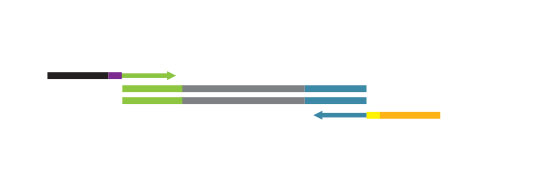
![]()
sequences required for cluster generation and to produce sufficient
material for quality control and sequencing. i7 and i5 indices can be
added during this step in order to be able to uniquely multiplex your
samples for the sequencing run.
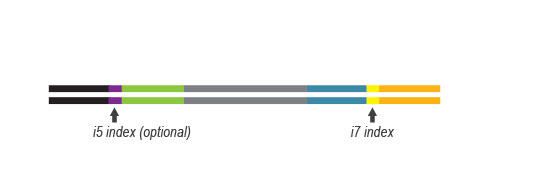
![]()
which can interfere with quantification.
![]()
Library quantification can be performed with standard protocols, e.g., microcapillary electrophoresis or qPCR. Produced libraries are compatible with single-read or paired-end sequencing reagents.
Featured Publications
List of the most recent SENSE mRNA-Seq for Illumina Publications.
List of the most recent SENSE mRNA-Seq for Ion Torrent Publications.
Automation
autoSENSE mRNA-Seq V2 for Illumina
autoSENSE V2 is the automated solution of the SENSE mRNA-Seq Library Prep Kit V2 for Illumina in combination with the software and the Automation Module, which is currently available for the Perkin Elmer Sciclone NGS Workstation in combination with the Zephyr Workstation for the post-PCR step. Please contact info@lexogen.com if you are interested in automating the SENSE protocol on any other liquid handler.
The main advantage of automating the RNA-Seq library preparation process is in reducing sample tracking errors while dramatically increasing throughput.
Fast and Fully Walk-Away Protocol
The whole autoSENSE V2 workflow is a complete walk-away protocol and 96 samples can be run within 9 hours, including about 2 hours of manual setup time. Since pre- and post-PCR can be run on separate machines the protocol time can be reduced by parallelizing the workflow.
Compatible with SENSE mRNA-Seq V2
The autoSENSE protocol is identical to the manual version of SENSE mRNA-Seq Library Prep Kit V2 and the software is downloadable from our website. With the Automation Module different library size selections can be performed and the workflow can be fully automated.
Flexibility of the Throughput
The autoSENSE kit is appropriate for preparing 9,216 barcoded libraries. The liquid handler program allows for processing of samples in multiples of 8 reactions (full columns of a 96-well plate). The reagents from a single kit can be distributed over several machine runs.
Avoiding Cross Contamination
Pre- and post PCR steps can be programmed on different machines to reduce the risk of cross-contamination of the pre-PCR samples by PCR products.
FAQ
Frequently Asked Questions
Please find a list of the most frequently asked questions below. If you cannot find the answer to your question here or want to know more about our products, please contact support@lexogen.com.
There are two major aspects of the SENSE technology contributing to its exceptional strand-specificity. Both of them are suppressing spurious second strand cDNA synthesis (see Figure 1), which introduces technical variation in detection of the antisense transcripts. Firstly, the protocol does not require RNA fragmentation as the insert size is determined by the distance between starter/stopper binding sites. Therefore, spurious second strand synthesis from the 5’ ends of RNA fragments is absent during reverse transcription. Secondly, when reverse transcriptase approaches the next hybridized primer during the first strand synthesis it is efficiently stopped, thus eliminating strand-displacement activity of the enzyme which can also cause spurious second strand synthesis.
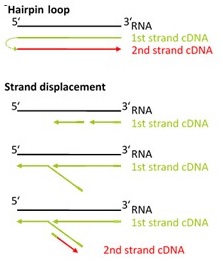
Figure 1. Spurious second strand synthesis mechanisms. Firstly, when RT reaches 5’ ends it adds 1-5 nucleotides in a non template fashion, like a terminal transferase. When it happens the primer binding domain is free again and it can associate with a new primer, then RT flips back onto the first strand cDNA in a hairpin loop manner and a spurious second strand is initiated from this 5’ end. Secondly, when one random hexamer is extended it displaces at least to some degree the extension product of the second hexamer. This “free” displaced first strand can be further primed again with a random primer and thus create a spurious second strand.
The SENSE technology avoids both hairpin loop and strand displacement artifacts, providing the basis for the excellent strand-specificity.
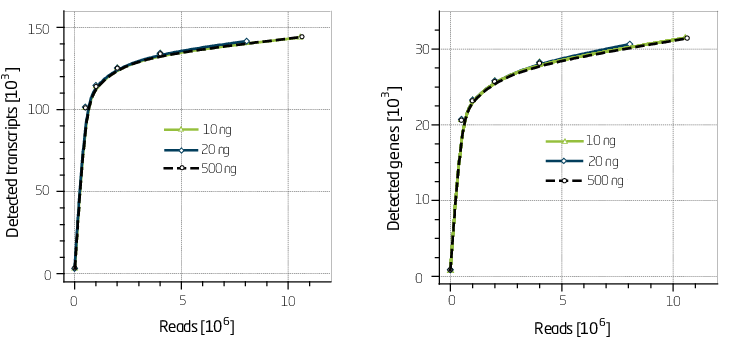
Figure 2. Discovery plots for 10 ng, 20 ng and 500 ng of input Universal Human Reference RNA (UHRR).
SENSE libraries have an excellent discovery rate on the transcript as well as the gene level.
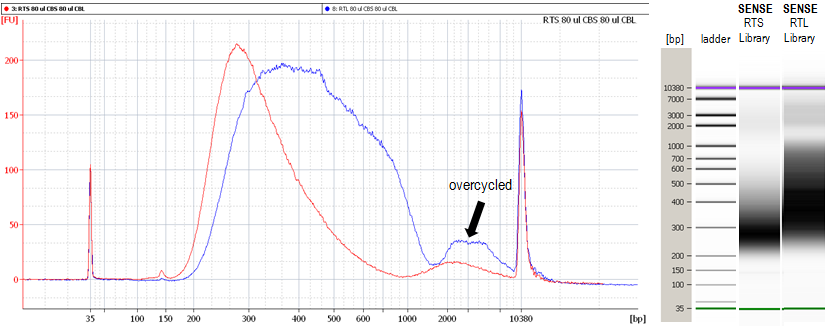
Figure 3. Bioanalyzer traces of RTS (red) and RTL (blue) synthesized SENSE mRNA-Seq for Illumina libraries with a second peak in high molecular weight regions due to overcycling.
The number of cycles for your endpoint PCR depends on the type RNA (tissue, organism), the RNA quality and the RNA input amount. The reference values given in Appendix B, p.23 and Appendix C, p.25 are based on Universal Human Reference RNA input and the mRNA content of other RNA sources might differ. To be on the safe side and prevent under- or overcycling of your sample we recommend doing a qPCR first. Therefore each SENSE Kit contains 8 additional PCR reactions. For more reactions we offer a PCR Add-on Kit for Illumina (020.96) with 96 additional PCR reactions.
Dilute the samples you want to check by qPCR by adding 2 µl of Elution Buffer (EB) or RNase-free water to the 17 µl of your eluted library from step 33. For determining the cycle number of your endpoint PCR, please use 5 µl of the P7 Primer 7000 in step 37 of the protocol. Insert 1.7 µl (of the diluted 19 µl double-stranded library, step 21) into a qPCR reaction. Simply add SYBR Green I (or an equivalent fluorophore) to the PCR reaction to a final concentration of 0.1x (diluted in DMSO). Make the total reaction volume up to 30 µl with EB. Conduct at least 35 cycles to make sure the amplification reaches the plateau. Afterwards take the fluorescence value where the plateau is reached and calculate where the fluorescence is at 50 % of the maximum (see Fig. 4). The value where the fluorescence reaches the maximum (plateau) is taken (15388) and the fluorescence at 50 % of this values (7694) shows which cycle number is optimal for the endpoint PCRs. For the sample in Fig. 3 this would be 15 cycles when using 1/10th of your sample. If the optimal cycle number lies within two values, it is recommended to always round up to the higher number in order to get more yield. As in the endpoint PCR 10x more cDNA will be used compared to the qPCR, three cycles can be subtracted from the determined cycle number, hence in this example 12 cycles should be used for the endpoint PCR. This is the cycle number you should use for the endpoint PCR using the remaining 17 µl of the template. Once the number of cycles for the endpoint PCR is established for one type of sample, you can use it in the following experiments. For higher yields you can increase the fluorescence level of the endpoint PCR up to 80 % without overcycling your sample.
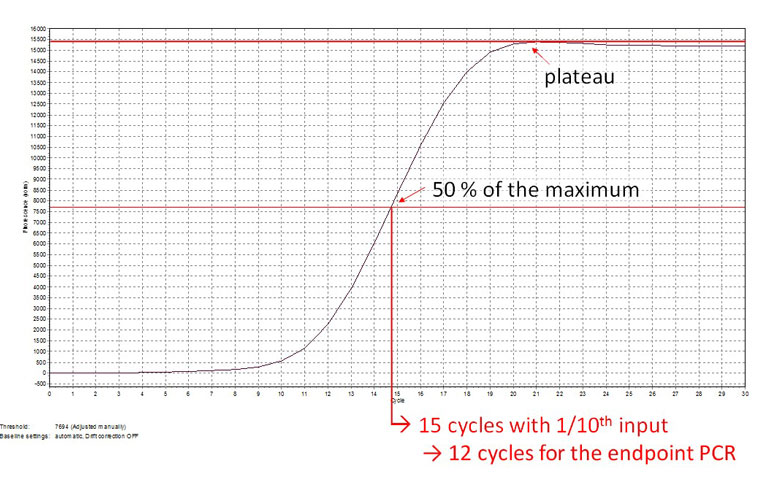
Figure 4: Calculation of the number of cycles for the endpoint PCR
Downloads
SENSE mRNA-Seq Library Prep Kit V2 for Illumina
![]() User Guide for Illumina – update 17.07.2019
User Guide for Illumina – update 17.07.2019
![]() PCR Add-on Kit for Illumina User Guide – update 03.01.2023
PCR Add-on Kit for Illumina User Guide – update 03.01.2023
![]() Lexogen i5 6 nt Dual Indexing Add-on Kits (5001-5096) User Guide – update 03.01.2023
Lexogen i5 6 nt Dual Indexing Add-on Kits (5001-5096) User Guide – update 03.01.2023
![]() SENSE Application Note
SENSE Application Note
![]() Lexogen i7 and i5 Index Sequences – update 05.05.2020
Lexogen i7 and i5 Index Sequences – update 05.05.2020
Material Safety Datasheets
MSDS Information can be found in the Documents page.
If you need more information about our products, please contact us through support@lexogen.com or directly under +43 1 345 1212-41.
SENSE Bioinformatics Data Analysis
Find more about the SENSE Data Analysis here.
Buy from our webstore
Need a web quote?
You can generate a web quote by Register or Login to your account. In the account settings please fill in your billing and shipping address. Add products to your cart, view cart and click the “Generate Quote” button. A quote in PDF format will be generated and ready to download. You can use this PDF document to place an order by sending it directly to sales@lexogen.com.
Web quoting is not available for countries served by our distributors. Please contact your local distributor for a quote.


